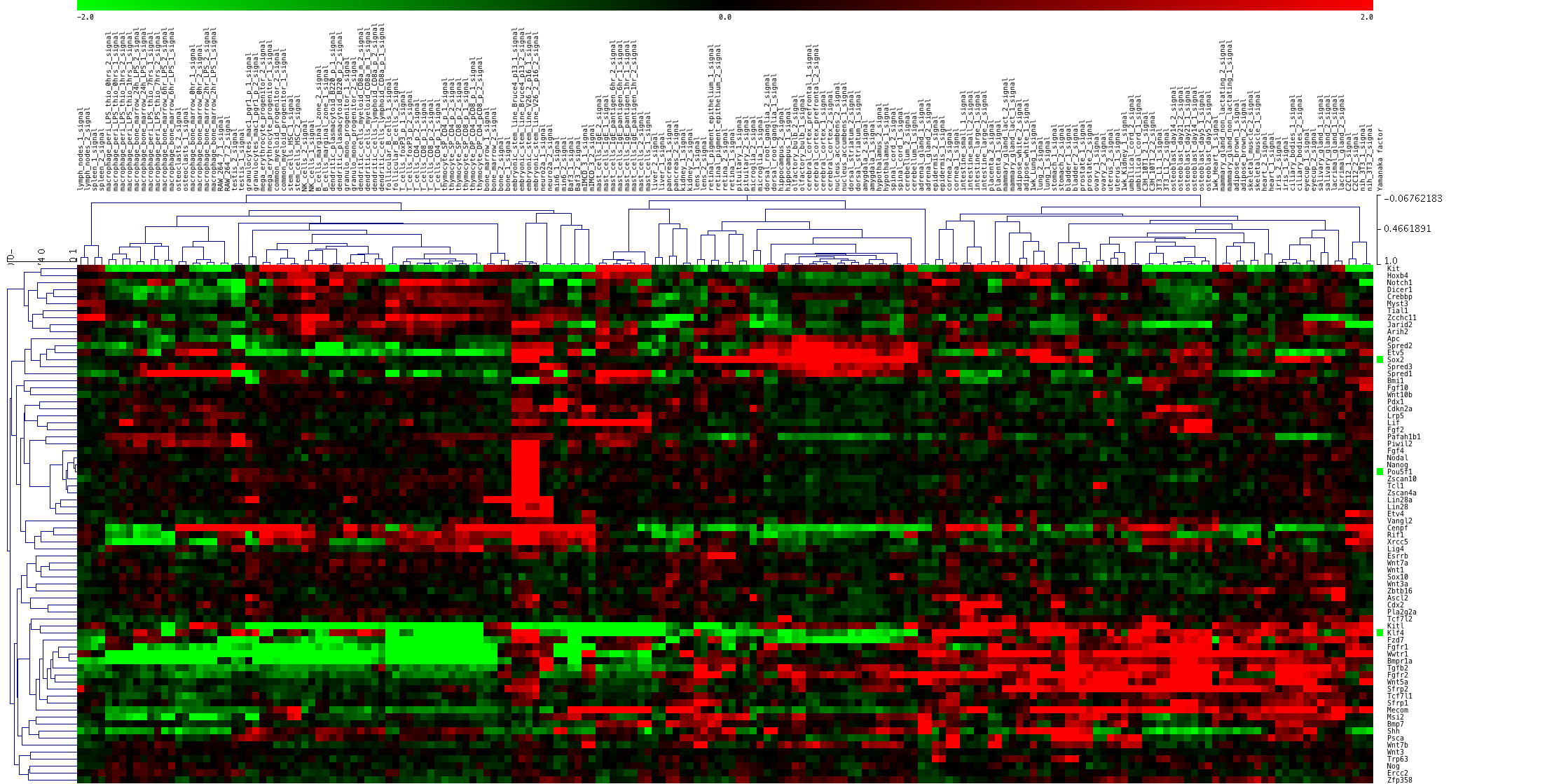
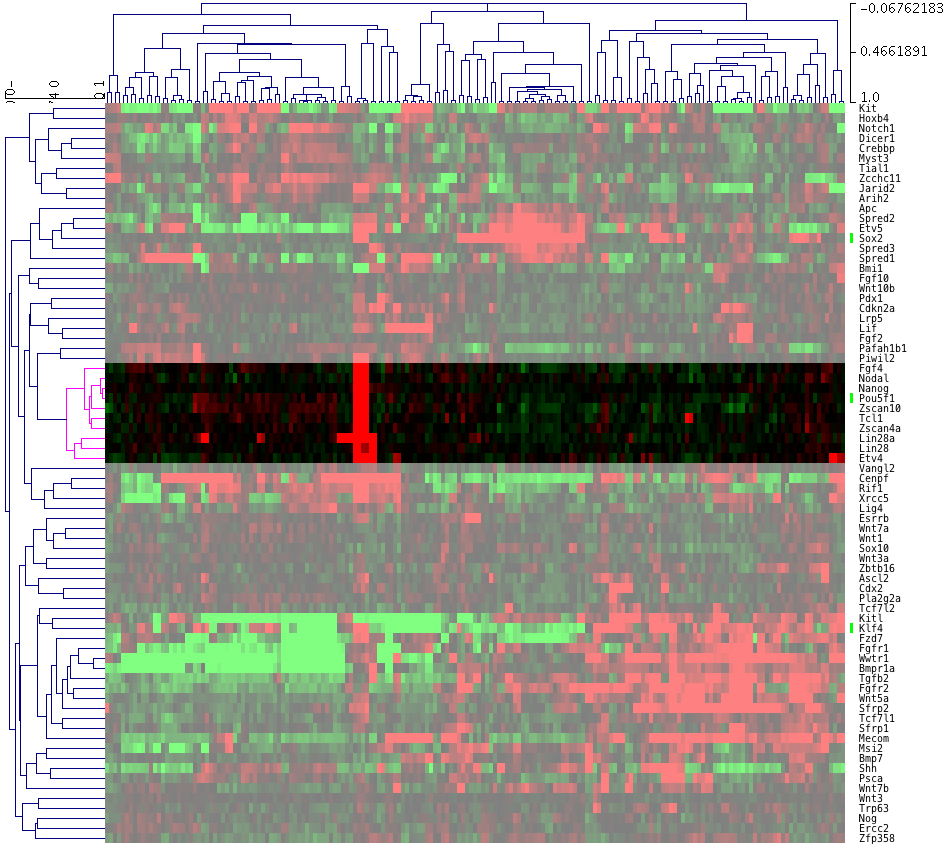
FASTQ, BAM (SAM) に続いて、よく利用されるのが、BED (べっど)形式のファイルです。
BED
BED は、Browser Extensible Data の略です。Browser (ブラウザ)は、UCSC のゲノムブラウザのことです。染色体(ゲノム)上の位置情報に、何らかのスコアを加えて表現するためのファイルです。
これもテキスト形式のファイルで、1行ごとに、位置情報 (chrom, chromStart, chromEnd) とスコア (name, score)、その他の情報をオプションで記述します。
最低限のデータとしては、下記のようなものです。(各項目の区切りはタブ文字)
chr1 100 200 geneA 1000 chr2 1000 2000 geneB 10
chrom は染色体の番号、chromStart は、指定したい配列の開始位置、chromEnd は終了位置です。name は、ブラウザに表示するときのラベル名、score は、表示したい任意の数字 (0-1000) です。ここまでが、BEDファイルに必須の項目です。残りのオプション部分にいろいろな情報を指定できるので、同じ BED ファイルでも様々なバリエーションがあります。
基本的には座標を指定するものなので、プロモーターやエンハンサーの位置を示したり、ChIP-seq の結果のピークの位置とスコアを表したり、様々なことに使用されています。
BED を元にさらに拡張されたフォーマットとして、bigBed, bedGraph があります。同様に、ゲノム上の位置(区間、領域)に情報を記述するものとして、WIG とそれを拡張、圧縮した bigWig などがあります。
bedtools
ゲノム上の位置情報どうしを演算するためのツールとして、 bedtools というソフトウェアがあります。bed で指定した配列の座標から、1000 base 上流の座標を求めたり、指定した座標の両端 500 から 1000 base の座標求めることができます。
さらにリファレンスゲノム(FASTAファイル)から、求めた座標に該当する領域の配列を抽出することも可能です。具体的な配列操作のイメージは、下記の解説が分かりやすいです。
その他の操作もイメージつきで解説されています。(このようなソフトウェアの解説は、まず、作成者の準備したドキュメントに目を通すことをお勧めします。有用なことが多く書かれています。)
http://bedtools.readthedocs.io/en/latest/content/bedtools-suite.html
Mac であれば、brew を使ってインストールできます。
brew install bedtools
* science タップを追加する必要があります。ない場合は上記のコマンドのログにその旨が表示されますので、それに従います。



{kind=link}