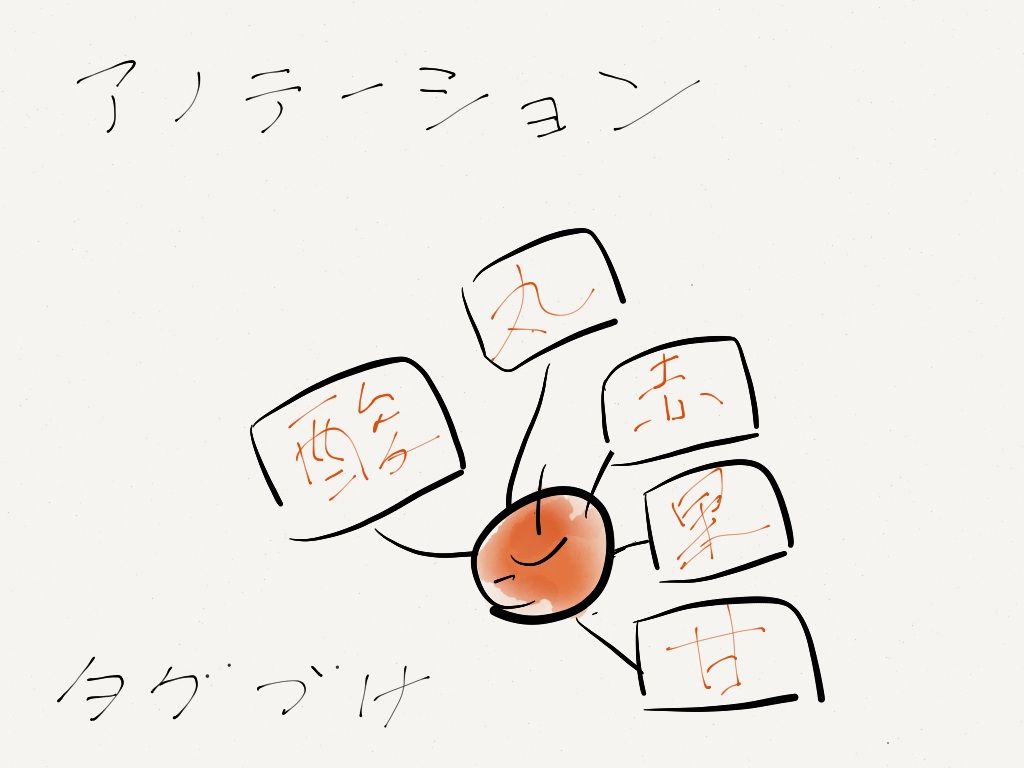
しかし、特定の遺伝子に GO を割り当てる(関連づける)作業を AmiGO が行っているわけではありません。その作業は、MGIなどの各コンソーシアムで行われています。上記の例でいうと、「りんご」に「赤」や「丸」、「甘」、「酸」などの用語を関連づける作業(=アノテーション)となります。このとき、各自が自由な用語を使ってアノテーションを行うと、後々、整理に困ります。そこで、あらかじめ使用できる用語を限定しておき、その限定された用語(用語集)を使って、アノテーションを行うようになったのです。遺伝子にアノテーションする場合に用いる用語集が、「GO」というわけです。
シグナル値そのものを書く以外に、ヒストグラムには便利な使い方があります。それは、ratio のヒストグラムです。まず、2サンプルのシグナル値から、ratio を計算します。対応するプローブ(遺伝子)ごとに、実験群のシグナル値をコントロールのシグナル値で割ることで算出できます。そして、シグナル値の代わりに、算出された ratio でヒストグラムを作成してみましょう。横軸に ratio の大きさ、縦軸に一定の区間のratioとなる遺伝子の個数を表します。また、横軸は対数目盛とします。シグナル値の場合と異なり、ratioのヒストグラムの形状としては、真ん中に高い山があり、左右の端にかけて、低くなる形状となります。
ratio のヒストグラム
真ん中の山は、ratio が1に近いことを表します。左右に分布しているのは、ratio が1以上、または、1以下ということですから、どちらかのサンプルでシグナル値が高いか、または低いということです。真ん中の山が高いことから、ほとんどの遺伝子で ratio が1付近、つまり、発現変動していない、ということが分かります。また、左右につれて山が低くなることから、大きく増減する遺伝子ほど、存在する数が少ないということが分かります。
さらに、真ん中付近の山の度数を足すと、どれくらいの遺伝子が発現変動していないか分かります。サンプルにも依りますが、ほとんどのケースで、3万個以上の遺伝子において、発現変動が見られない(0.5 < ratio < 2)ことが多いです。発現変動したと判定される遺伝子は、たかだか数千個です。