似ているサンプルを探したい場合は、クラスタリングで見つけることができます。 MeV を用いた解析例を示します。
階層的クラスタリングで似ているサンプルを探す
似ているサンプルを探していたい場合、クラスタリングのアルゴリズムとしては、「階層的クラスタリング」の手法がよく用いられます。
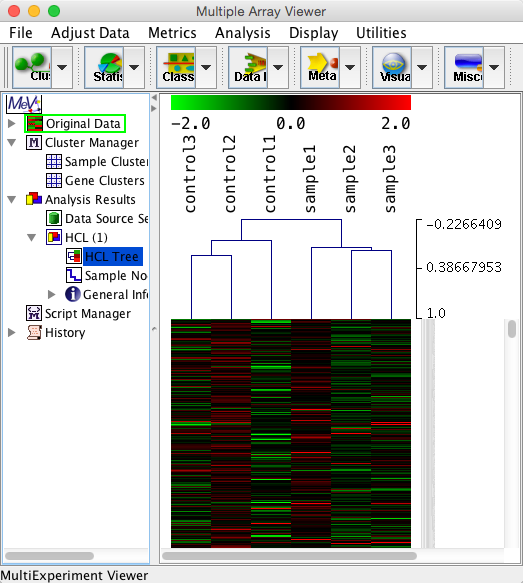
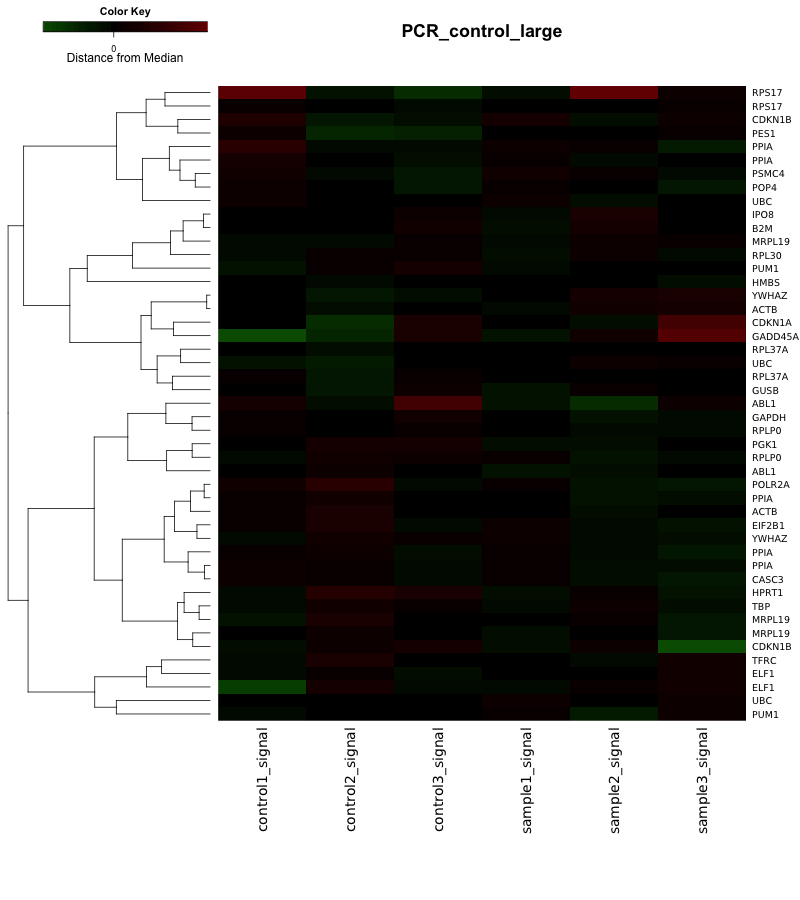
階層的クラスタリングでは、sample2 に一番似ているのは、sample3、その次は、sample1 というように、似ている順序が示されます。また、その順序は、系統樹(ツリー)で表現されます。
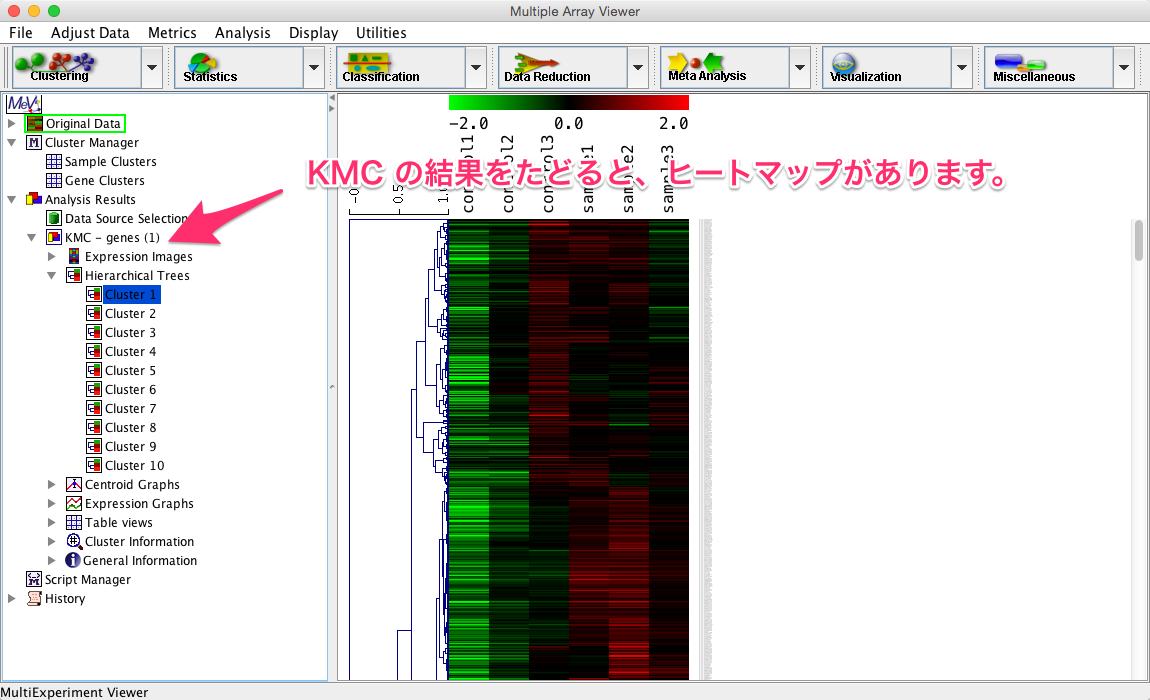
最終的には、各サンプルのヒートマップの上部(または下部)に、そのツリーを組み合わせてものが結果として用いられます。ツリーとヒートマップは独立していることに留意してください。ヒートマップを書かなくてもツリーは算出できますし、ツリーを算出したからといって、ヒートマップができるわけではありません。(ツリーの結果だけ、ヒートマップに後付けされることもあります。)MeV などのツールを用いれば、クラスタリングの結果が自動的にヒートマップになるので、誤解しやすい点です。
例えば、解析例1のデータをサンプル方向でクラスタリングすると下図のようになります。あえて、遺伝子方向のクラスタリングは行っていません。そのため、ヒートマップの色は分かれているように見えていませんが、どのサンプルが似ているかはツリーから確認できます。